
A-OpenEnv: An Adaptive Curriculum Layer for Verifiable AI Environments
A reinforcement-learning-inspired framework for making AI agent evaluation adaptive, reproducible, and difficulty-aware.
Building A-OpenEnv: An Adaptive Curriculum Layer for Verifiable AI Environments
Inspired by reinforcement learning, A-OpenEnv explores how verifiable AI environments can adapt task difficulty based on agent performance.
Most AI agent evaluations use fixed-difficulty tasks. That is useful for benchmarking, but it has a limitation: the environment does not adapt.
If the tasks are too easy, the agent quickly saturates. If the tasks are too hard, the agent fails repeatedly and gives us very little useful signal. In both cases, the evaluation becomes less informative.
That is the idea behind A-OpenEnv.
My original interest came from reinforcement learning and agent training systems. In RL, the environment matters a lot. The agent acts, the environment responds, and the feedback signal decides what kind of learning is possible. But before jumping into a full RL training loop, I wanted to build a clean environment layer where tasks are verifiable, difficulty can adapt, and evaluation is reproducible.
A-OpenEnv is that layer.
It is an adaptive curriculum layer for OpenEnv-style environments. It sits between an agent and a verifiable environment, tracks the agent's performance, and adjusts the difficulty of future tasks.
The goal is not to replace the environment. The goal is to make the environment adaptive.
The Problem With Fixed-Difficulty Evaluation
OpenEnv-style environments are useful because they can produce verifiable outcomes.
Instead of depending only on human labels or learned reward models, the environment can programmatically check whether an agent completed a task correctly.
For example:
Did the agent solve the reasoning problem?
Did the selected patch fix the bug?
Did the submitted code pass the test cases?
Did the agent execute a valid task graph plan?
This makes the environment useful for evaluating agents because correctness is not subjective.
But there is still a problem.
Most environments expose tasks at a fixed level of difficulty. That makes evaluation easier to run, but it does not reflect how difficulty should change as the agent's observed performance changes.
A fixed benchmark usually asks:
Can the agent solve this task?
A-OpenEnv tries to ask a slightly better question:
How does the agent perform when task difficulty adapts to its current capability?
This is also related to why RL environments are interesting. In reinforcement learning, the agent is not just answering isolated prompts. It interacts with an environment over time and receives feedback based on its actions.
A-OpenEnv does not implement a full RL algorithm, but it borrows from that environment-centric way of thinking:
define a task environment
make the outcome verifiable
expose observations, actions, rewards, and completion status
track performance over episodes
adapt the environment as capability changes
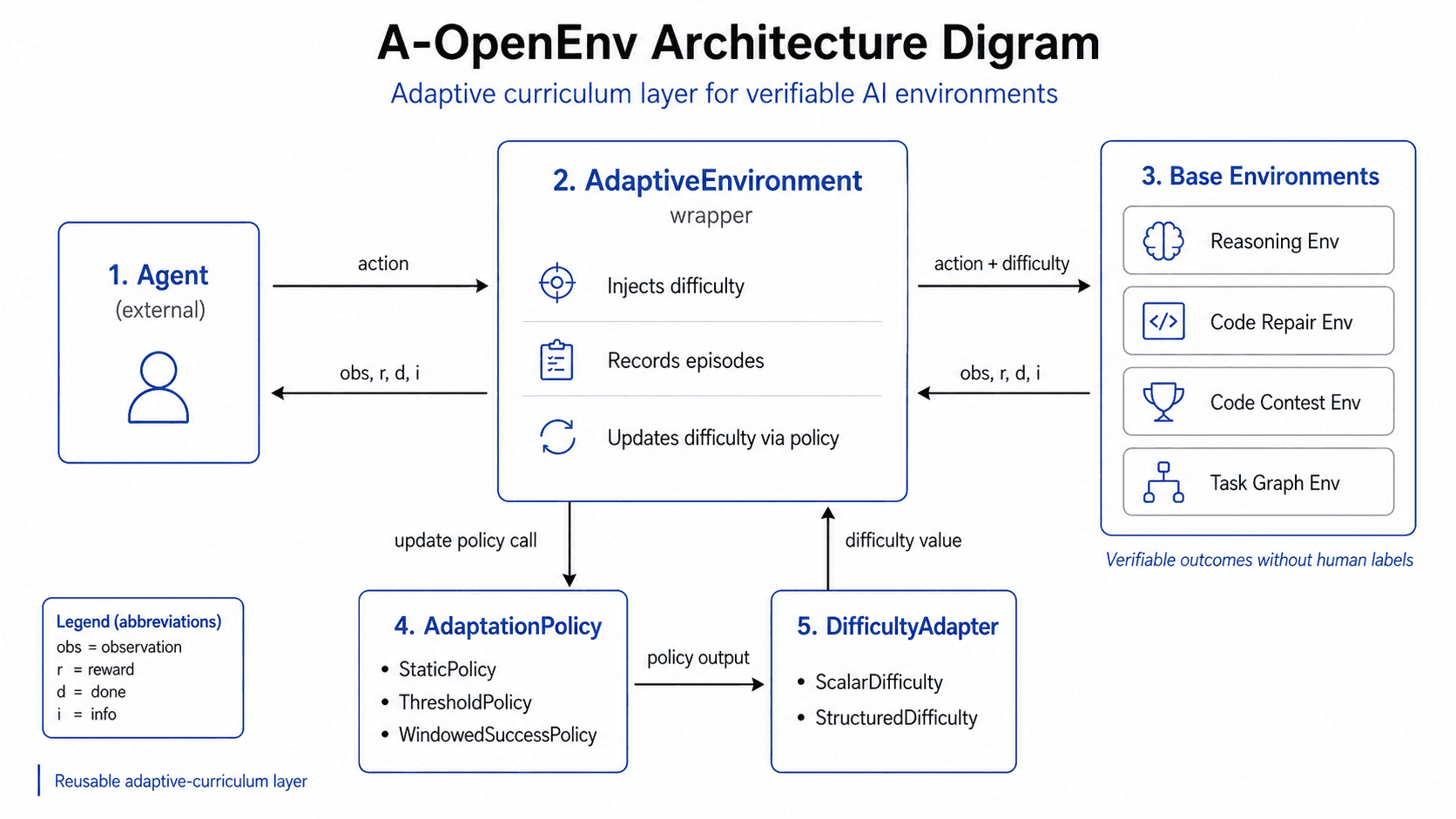
What Is A-OpenEnv?
A-OpenEnv is a reusable adaptive wrapper for verifiable environments.
It wraps a base environment that exposes familiar methods like:
reset()
step(action)
state()
The base environment remains responsible for task generation, state transitions, and grading.
A-OpenEnv adds a layer around it that handles:
difficulty injection
episode tracking
performance history
policy-based difficulty updates
evaluation outputs
reproducible experiment runs
At a high level, the loop looks like this:
Agent
|
| action
v
AdaptiveEnvironment
|
| action + current difficulty
v
Base Environment
|
| observation, reward, done, info
v
AdaptiveEnvironment
|
| adapted state + diagnostics
v
Agent
The agent interacts with the wrapper. The wrapper interacts with the environment. The environment still decides what a valid task is and how correctness is checked.
Core Architecture
A-OpenEnv is built around five main components:
AdaptiveEnvironmentDifficultyAdapterAdaptationPolicyBase environmentsEvaluation and tracking pipeline
Each component has a specific responsibility.
AdaptiveEnvironment
AdaptiveEnvironment is the main wrapper.
It exposes the same basic interaction pattern as the base environment:
observation = env.reset()
observation, reward, done, info = env.step(action)
state = env.state()
Before a new episode starts, the wrapper injects the current difficulty into the base environment.
When the episode ends, the wrapper records the episode result and asks the adaptation policy whether the next task should become easier, harder, or remain unchanged.
A simplified flow looks like this:
reset()
-> set base environment difficulty
-> reset base environment
-> return observation
step(action)
-> forward action to base environment
-> receive observation, reward, done, info
-> if episode is done:
-> record episode stats
-> update difficulty using policy
-> return observation, reward, done, info
A key detail is that the wrapper does not change the base environment difficulty in the middle of an episode. If difficulty changes, it applies to the next episode.
That avoids unstable behavior where an in-progress task changes difficulty while the agent is still solving it.
DifficultyAdapter
Different environments may represent difficulty differently.
A simple environment may use scalar difficulty:
difficulty = 0.4
A more complex environment may use structured difficulty:
{
"algorithmic_depth": 0.4,
"input_scale": 0.6,
"edge_cases": 0.3
}
The DifficultyAdapter hides those details from the wrapper. It validates difficulty values, clamps them within allowed bounds, sets difficulty on the base environment, reads difficulty from the base environment, describes the current difficulty, and aggregates structured difficulty when needed.
This keeps the adaptive wrapper generic. A scalar value is simple to configure and visualize, while structured difficulty is more expressive because task difficulty is rarely one-dimensional. For example, a code contest task may become harder because it needs a deeper algorithm, larger input handling, more edge-case coverage, or a combination of all three.
AdaptationPolicy
AdaptationPolicy decides how difficulty changes over time.
A-OpenEnv currently supports three policy types.
Static Policy
StaticPolicy keeps difficulty fixed.
This is useful as a baseline. If the difficulty does not change, we can compare adaptive evaluation against non-adaptive evaluation.
Threshold Policy
ThresholdPolicy updates difficulty based on recent performance.
For example:
if success is high:
increase difficulty
if success is low:
decrease difficulty
otherwise:
keep difficulty unchanged
This is simple and easy to debug. It works well as a first adaptive policy.
Windowed Policy
WindowedSuccessPolicy uses a rolling window of recent episodes.
Instead of reacting to a single success or failure, it looks at recent performance over a window.
For example:
last 32 episodes -> compute success rate
if success rate >= upper threshold:
increase difficulty
if success rate <= lower threshold:
decrease difficulty
otherwise:
keep difficulty unchanged
This makes adaptation less noisy because one lucky success or one unlucky failure should not immediately change the curriculum.
Reference Environments
To test the generality of the wrapper, A-OpenEnv includes four reference environments. These environments were chosen because they represent different kinds of agent interaction.
Reasoning evaluates single-step verifiable reasoning where the agent returns an answer and the grader checks it programmatically. Example task families include arithmetic chains, symbolic transformations, and constraint satisfaction. Example difficulty axes: steps, distractors, abstraction.
Code repair evaluates bug-fixing tasks where the agent selects the correct patch from candidate fixes. Example task families include off-by-one bugs, wrong conditionals, wrong constants, missing edge-case branches, and operator semantic bugs. Example difficulty axes: files, hidden_tests, ambiguity.
Code contest evaluates competitive-programming-style code submissions checked by executable tests. Example task families include shipping capacity, count inversions, weighted interval scheduling, and shortest subarray at least k. Example difficulty axes: algorithmic_depth, input_scale, edge_cases.
Task graph planning evaluates multi-step planning over dependency graphs where the agent must choose valid actions over time. Example task families include linear chains, shallow DAGs, fanout graphs, diamond dependencies, and bottleneck hubs. Example difficulty axes: horizon, branching, partial_observability.
This mix is useful because the wrapper is not tied to one task type. It can handle single-step tasks, patch-selection tasks, executable code-grading tasks, and multi-step planning tasks.
ID and OOD Task Generation
A-OpenEnv supports both in-distribution and out-of-distribution task generation.
This matters because an agent may perform well on task families it has seen before but fail when the structure shifts.
For example, the reasoning environment may include in-distribution arithmetic and symbolic tasks, while the out-of-distribution split may combine arithmetic and symbolic operations in the same task.
This helps answer two separate questions:
How well does the agent perform on familiar task families?
How well does the agent generalize to shifted task families?
The framework keeps these paths separate so evaluation can report ID and OOD behavior clearly.
Reproducibility
Reproducibility is a core design goal.
Every generator is seeded. Given the same seed, episode number, difficulty, and split, the same task should be generated again.
This matters for debugging. If an agent fails on episode 42 with seed 11, we should be able to reproduce that exact task later.
It also matters for comparison. If two agents are evaluated on different random tasks, their results are harder to compare.
A-OpenEnv is designed so experiments can be repeated and inspected.
Evaluation Pipeline
The evaluation pipeline is config-driven.
A YAML config defines:
environment name
policy name
difficulty mode
number of episodes
seeds
ID/OOD evaluation setting
output directory
adaptation settings
environment-specific settings
The runner then executes the evaluation.
The high-level flow is:
YAML config
-> validate config
-> build base environment
-> build difficulty adapter
-> build adaptation policy
-> wrap with AdaptiveEnvironment
-> run episodes
-> collect history
-> export metrics
-> generate plots
-> export report
The output includes:
metrics.csvtrajectories.jsonlsummary.jsondifficulty curve plotreward curve plotmarkdown report
This makes the framework useful not only for running environments, but also for analyzing how difficulty changes over time.
Live E2E Run: Gemini on Code Contest
To check that the wrapper works with a real agent and not only a deterministic test baseline, I ran a live end-to-end evaluation on the code contest environment.
The setup was:
environment:
code_contestwrapper:
AdaptiveEnvironmentpolicy:
thresholddifficulty mode: structured
model agent:
gemini-3.1-flash-lite-previewrate limit: 15 requests per minute
splits: ID and OOD
seeds:
17,23episodes: 30 per seed per split, 120 total
max attempts per episode: 4
In this run, Gemini generated Python submissions. The CodeContestEnv grader executed those submissions against public and hidden tests. After each episode, the adaptive wrapper recorded the result and updated structured difficulty for the next task.
The result was:
ID split
- Episodes:
60 - Success rate:
1.00 - Average reward:
1.00 - First difficulty:
0.35 - Final difficulty:
0.7833
OOD split
- Episodes:
60 - Success rate:
1.00 - Average reward:
1.00 - First difficulty:
0.35 - Final difficulty:
0.7833
All 120 live model episodes were accepted on the first attempt.
That is a useful result, but it needs the right interpretation.
This does not mean the model learned during the run. The model weights were fixed. What changed was the environment difficulty. Because the live agent kept succeeding, the adaptive wrapper increased the aggregate difficulty from 0.35 to 0.7833 for each seed and split trajectory.
The main takeaway is that the full loop works:
live LLM agent
-> adaptive wrapper
-> code contest task
-> executable grading
-> episode history
-> next difficulty update
The second takeaway is that this particular environment configuration is saturated for gemini-3.1-flash-lite-preview. To expose a performance frontier, the next experiment should make the code contest environment harder, add more difficult task families, reduce available feedback, or lower the number of attempts.
The run produced the usual evaluation artifacts:
metrics.csvtrajectories.jsonlgenerations.jsonlsummary.jsondifficulty_curve.pngreward_curve.pngmarkdown report
OpenEnv Compatibility
The goal of A-OpenEnv is not to loosely imitate OpenEnv-style environments.
The goal is to keep compatibility as a first-class design constraint.
That means the base environments should remain usable through OpenEnv-core compatible adapters and app modules while A-OpenEnv adds adaptive curriculum behavior on top.
The project includes app modules and adapters for exposing bundled environments through OpenEnv-compatible APIs.
This is important because the adaptive layer should not force users to abandon the environment interface they already expect.
What Makes This Useful?
A-OpenEnv is useful because it turns static evaluation into adaptive evaluation.
Instead of only measuring whether an agent can solve a fixed task set, we can inspect how the agent behaves as difficulty changes.
This creates more useful evaluation curves.
For example:
Does the agent continue to succeed as difficulty increases?
Does performance collapse after a certain difficulty level?
Does the agent handle ID tasks but fail on OOD tasks?
Which difficulty axes cause the most failures?
Does a rolling-window policy produce smoother evaluation than a threshold policy?
These questions are difficult to answer with a fixed benchmark alone.
What This Project Is Not
A-OpenEnv is not a replacement for OpenEnv.
It is a wrapper layer around OpenEnv-style environments.
A-OpenEnv is also not a full RL training framework by itself.
The current focus is adaptive evaluation, reproducible experiments, and verifiable task environments.
It can potentially be used as part of an RL-style or agent-training loop later, but the first goal is to build a clean adaptive environment layer.
This distinction matters.
The project should not be described as a complete reinforcement learning framework unless actual RL training loops, policies, optimization logic, and training integrations are added.
The more accurate description is:
A-OpenEnv is an adaptive curriculum and evaluation layer for verifiable AI environments, motivated by RL-style environment design.
Design Lessons
The biggest design lesson was that the adaptive layer should not own task logic.
It should not know how to solve a reasoning task.
It should not know how to fix a code bug.
It should not know how to solve a graph planning problem.
It should only know how to:
set difficulty
observe results
track history
update future difficulty
expose diagnostics
That keeps the system modular.
It also makes it easier to add new environments.
If a new environment supports reset(), step(), state(), and a difficulty adapter, it can be wrapped by A-OpenEnv.
Future Work
The next improvements are stronger OpenEnv compatibility tests, broader real-agent baselines, smarter structured difficulty adaptation, and richer ID/OOD reporting. I also want to explore RL-style training loop integration, where environment rewards can act as training signals and adaptive difficulty can behave like curriculum scheduling. The important point is that this remains future work: the current project is an adaptive evaluation layer, not a complete RL framework.
Links
GitHub repo: https://github.com/RoopeshK30/A-OpenEnv